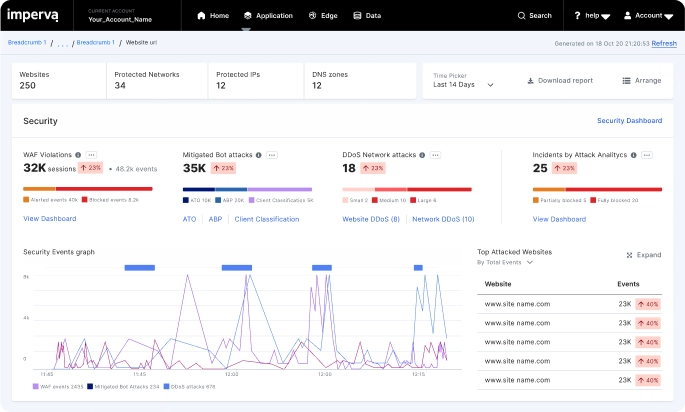
2024 Bad Bot Report Explore the latest trends & impact of unmanaged bot traffic
Get the report

Comprehensive digital security
Imperva latest news

KuppingerCole Report: Why Your Organization Needs Data-Centric Security
Read more
Data Security in 2024: Unveiling Strategies Against AI-Driven Cyber Threats
Watch webinarThales & Imperva join forces to create a global leader in cybersecurity
Find out moreEnterprises move to Imperva for
world class security

Faster response
Accelerate containment with 3-second DDoS mitigation and same day blocking of zero-days.

Deeper protection
Secure applications and data deployed anywhere with positive security models.

Consolidated security
Consolidate security point products for detection, investigation, and management under one platform.
Imperva products are quite exceptional

Protecting modern web applications
Enterprises need security at multiple layers to effectively protect against different types of attacks and reduce risk.
Learn more
Assure data compliance and privacy
Streamline processes and know what data you have, where it is stored, how it is handled, and by whom.
Learn more
Prevent account takeover fraud
Have confidence that your web applications are protected against today’s automated account fraud.
Learn more
Stop software supply chain attacks
Gain control of risky behaviors between custom and third-party application components.
Learn more
Mitigate malicious data activity
Protect against malicious data access to defend the end of the attack chain as XDR solutions cannot.
Learn more
Automate insider threat management
Use continuous visibility and automation to shut down high-risk privileged data access.
Learn more
Ensure consistent application availability
Automatically optimize and protect at the edge to minimize the likelihood of downtime with zero performance impact.
Learn more
Embed security into DevOps
Provide developers with the tools they need to adopt the latest technology and prove it’s safe for management.
Learn more
Securely move your data to the cloud
Grow beyond compliance monitoring to secure cloud data with minimal disruption to users during transition.
Learn moreRecognized leadership

API Security & Management Overall Leader
Imperva named an Overall Leader in the 2023 KuppingerCole Leadership Compass for API Security & Management
Read the report

Read the report

Imperva named a security leader in the SecureIQLab CyberRisk Report
2022 Cloud Web Application Firewall (WAF) CyberRisk Validation Comparative Report
Read the report
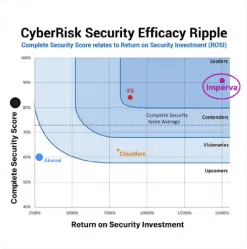
Read the report
Data Security Platform Overall Leader
Imperva named an overall leader in the 2023 KuppingerCole Leadership Compass for Data Security Platforms
Read the report

Read the report
Recognized as a market, product, and innovation leader
Imperva named an overall leader in the 2022 KuppingerCole Leadership Compass for Web Application Firewalls
Read the report

Read the report
Delivers DDoS protection in an application suite
The Forrester Wave™: DDoS Mitigation Solutions, Q1 2021
Read the report
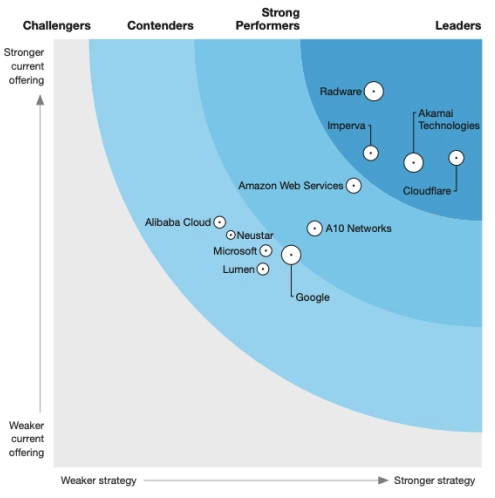
Read the report
Expansive Web Application and API Protection
Imperva named a Fast Mover and Innovator in GigaOm Radar for Application and API Protection
Read the report
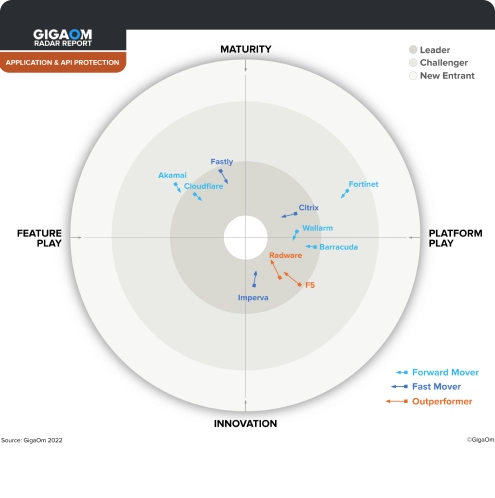
Read the report