
What Are Bots
An Internet bot is a software application that runs automated tasks over the internet. Tasks run by bots are typically simple and performed at a much higher rate compared to human Internet activity.
Some bots are legitimate—for example, Googlebot is an application used by Google to crawl the Internet and index it for search. Other bots are malicious—for example, bots used to automatically scan websites for software vulnerabilities and execute simple attack patterns.
What Is a Botnet
There are many types of malware that infect end-user devices, with the objective of enlisting them into a botnet. Any device that becomes infected starts communicating with a Command and Control (C&C) center and can perform automated activities under the attacker’s central control.
Many threat actors are actively engaged in building massive botnets, with the biggest ones spanning millions of computers. Often, the botnet can grow itself, for example by using infected devices to send out spam emails, which can infect more machines.
Botnet owners use them for large-scale malicious activity, commonly Distributed Denial of Service (DDoS) attacks. Botnets can also be used for any other malicious bot activity, such as spam bots or social bots (described below), albeit on a much larger scale.

Types of Bots
There are many types of bots active on the Internet, both legitimate and malicious. Below are several common examples.
Spider Bots
Spider bots, also known as web spiders or crawlers, browse the web by following hyperlinks, with the objective of retrieving and indexing web content. Spiders download HTML and other resources, such as CSS, JavaScript, and images, and use them to process site content.
If you have a large number of web pages, you can place a robots.txt file in the root of your web server, and provide instructions to bots, specifying which parts of your site they can crawl, and how frequently.
Scraper Bots
Scrapers are bots that read data from websites with the objective of saving them offline and enabling their reuse. This may take the form of scraping the entire content of web pages or scraping web content to obtain specific data points, such as names and prices of products on eCommerce sites.
Web scraping is a gray area -in some cases, scraping is legitimate and may be permitted by website owners. In other cases, bot operators may be violating website terms of use, or worse—leveraging scraping to steal sensitive or copyrighted content.
Spam Bots
A spambot is an Internet application designed to gather email addresses for spam mailing lists. A spam bot can gather emails from websites, social media websites, businesses and organizations, leveraging the distinctive format of email addresses.
After attackers have amassed a large list of email addresses, they can use them not only to send spam email, but also for other nefarious purposes:
- Credential cracking—pairing emails with common passwords to gain unauthorized access to accounts.
- Form spam—automatically inserting spam, such as ads or malware links, into forms on popular websites, typically comment or feedback forms.
Apart from the direct damage caused to end-users and organizations affected by spam campaigns, spam bots can also choke server bandwidth and increase costs for Internet Service Providers (ISPs).
Social Media Bots
Bots are operated on social media networks, and used to automatically generate messages, advocate ideas, act as a follower of users, and as fake accounts to gain followers themselves. It is estimated that 9-15% of Twitter accounts are social bots.
Social bots can be used to infiltrate groups of people and used to propagate specific ideas. Since there is no strict regulation governing their activity, social bots play a major role in online public opinion.
Social bots can create fake accounts (although this is becoming more difficult as social networks become more sophisticated), amplify the bot operator’s message, and generate fake followers/likes. It is difficult to identify and mitigate social bots, because they can exhibit very similar behavior to that of real users.
Download Bots
Download bots are automated programs that can be used to automatically download software or mobile apps. They can be used to influence download statistics, for example to gain more downloads on popular app stores and help new apps get to the top of the charts. They can also be used to attack download sites, creating fake downloads as part of an application-layer Denial of Service (DoS) attack.
Ticketing Bots
Ticketing Bots are an automated way to purchase tickets to popular events, with the aim of reselling those tickets for a profit. This activity is illegal in many countries, and even if not prohibited by law, it is an annoyance to event organizers, ticket sellers and consumers.
Ticketing bots tend to be very sophisticated, emulating the same behaviors as human ticket buyers. In many ticketing domains, the proportion of tickets purchased by automated bots ranges between 40-95%.
How To Detect Bot Traffic in Web Analytics
Following are a few parameters you can use in a manual check of your web analytics, to detect bot traffic hitting a website:
- Traffic trends—abnormal spikes in traffic might indicate bots hitting the site. This is particularly true if the traffic occurs during odd hours.
- Bounce rate—abnormal highs or lows may be a sign of bad bots. For example, bots that hit a specific page on the site and then switch IP will appear to have 100% bounce.
- Traffic sources—during a malicious attack, the primary channel sending traffic is “direct” traffic and the traffic will consist of new users and sessions.
- Server performance—a slowdown in server performance may be a sign of bots.
- Suspicious IPs/geo-locations—an increase in activity to an unknown IP range or a region you don’t do business in.
Suspicious hits from single IPs—a big number of hits from a single IP. Humans typically request a few pages and not others, whereas bots will often request all pages. - Language sources—seeing hits from other languages your customers do not typically use.
All of the above are only rough indicators of bot activity. Be aware that sophisticated malicious bots can generate a realistic, user-like signature in your web analytics. It is advisable to use a dedicated bot management solution that provides full visibility of bot traffic.
How to Stop Bot Traffic: Basic Mitigation Measures
There are a few simple measures you can take to block at least some bots and reduce your exposure to bad bots:
- Place robots.txt in the root of your website to define which bots are allowed to access your website. Keep in mind, this is only effective for managing the crawl patterns of legitimate bots, and will not protect against malicious bot activity.
- Add CAPTCHA on sign-up, comment, or download forms. Many publishers and premium websites place CAPTCHA to prevent download or spam bots.
- Set a JavaScript alert to notify you of bot traffic. Having contextual JavaScript in place can act as a buzzer and alert you whenever it sees a bot or similar element entering a website.
How Do Bots Evade Detection?
Bot technology has evolved over the past decade. Originally, bots were a script hitting a website to retrieve data or perform actions. These scripts would not accept cookies and did not parse JavaScript, making them very easy to detect.
Over time bots got more sophisticated, accepting cookies and parsing JavaScript, but they could still be detected quite easily because they used dynamic website elements less than human users.
The next evolution was the use of headless browsers like PhantomJS—these can process website content in its entirety. Although these browsers are more sophisticated than basic bots, headless browsers still cannot perform all actions that real users can.
The most advanced types of bots are based on the Chrome browser and are almost indistinguishable from real users. These bots even simulate human activity such as clicking on-page elements.
Advanced Bot Mitigation Techniques
As bots evolved, so did mitigation techniques. There are currently three technical approaches to detecting and mitigating bad bots:
- Static approach—static analysis tools can identify web requests and header information correlated with bad bots, passively determining the bot’s identity, and blocking it if necessary.
- Challenge-based approach—you can equip your website with the ability to proactively check if traffic originates from human users or bots. Challenge-based bot detectors can check each visitor’s ability to use cookies, run JavaScript, and interact with CAPTCHA elements. A reduced ability to process these types of elements is a sign of bot traffic.
- Behavioral approach—a behavioral bot mitigation mechanism looks at the behavioral signature of each visitor to see if it is what it claims to be. Behavioral bot mitigation establishes a baseline of normal behavior for user agents like Google Chrome, and sees if the current user deviates from that behavior. It can also compare behavioral signatures to previous, known signatures of bad bots.
By combining the three approaches, you can overcome evasive bots of all types, and successfully separate them from human traffic. You can use these approaches independently or you can rely on bot mitigation services to perform techniques for you.
Bot mitigation services are automated tools that use the above methods to identify bots. These services can be used to monitor API traffic and detect if it is legitimate machine traffic or bad bots “milking” your API.
Advanced bot mitigation services use rate limiting for each requesting client or machine, instead of an entire IP, allowing it to limit crawling from bad bots. Once a bot is identified, these services can propagate the information across the network, to ensure the same bot cannot access your site or API again.
Imperva Bot Management
Imperva’s bot management solution uses all three approaches covered above—static, challenge-based and behavior-based—to investigate each visitor on your site, whether human or not, and match it with a behavioral ID. It can effectively protect against malicious bots while ensuring that legitimate bots and human users have uninterrupted access to your site.
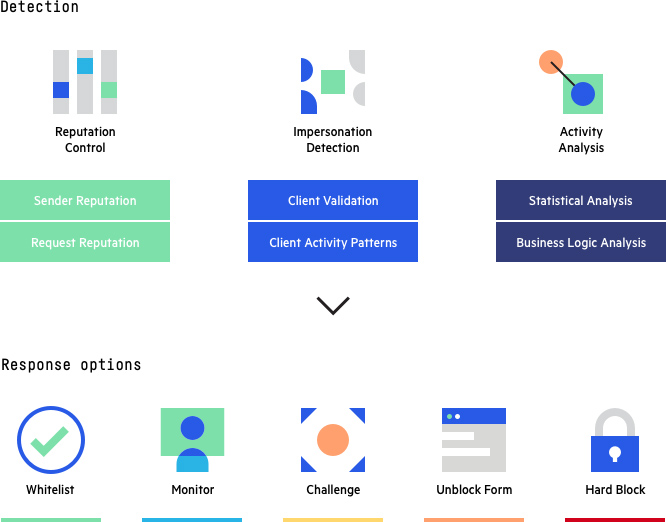
Imperva Bot Management: Detection methods and response options
In addition to helping mitigate bad bot activity, Imperva provides multi-layered protection to make sure websites and applications are available, easily accessible and safe. The Imperva application security solution includes:
- API security—protects APIs from bots and human attackers by ensuring only desired traffic can access your API endpoint, as well as detecting and blocking exploits of vulnerabilities.
- DDoS Protection—maintain uptime in all situations. Prevent any type of DDoS attack, of any size, from preventing access to your website and network infrastructure.
- CDN—enhance website performance and reduce bandwidth costs with a CDN designed for developers. Cache static resources at the edge while accelerating APIs and dynamic websites.
- Web Application Firewall—permit legitimate traffic and prevent bad traffic. Safeguard your applications at the edge with an enterprise‑class cloud WAF.
- RASP—keep your applications safe from within against known and zero‑day attacks. Fast and accurate protection with no signature or learning mode.
- Account Takeover Protection—uses an intent-based detection process to identify and defends against attempts to take over users’ accounts for malicious purposes.













